In this article, I am going to change the SSH port from 22 to 52241 and create a new firewall rule in VPC. Please do your own research and make sure you understand the impact, especially on a production environment.
When you deploy a new docker container on GCE, you can SSH into the host machine ( VM ). This is simply because the IP address is pointing to the host machine. But what about the docker container that runs on it? In this case, you must use docker exec or the gcloud command-line tool in order to get access to the container, which can be pretty time consuming over time.
|
|
docker exec -ti {docker-container} bash |
I am working on a project where I need direct access to my alpine docker container on port 22 or any other port. As you can see in the below output, no ports are exposed for my container.
|
|
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 36a7b16b17dc gcr.io/tobiasforkel/magento2:latest "/usr/bin/supervisor…" 15 minutes ago Up 15 minutes klt-tobiasforkel-2-kwkm 4597512dd812 gcr.io/stackdriver-agents/stackdriver-logging-agent:0.2-1.5.33-1-1 "/entrypoint.sh /usr…" 16 minutes ago Up 16 minutes stackdriver-logging-agent |
This is mainly because the docker container shares the network with the host. Source
Containerized VMs launch containers with the network set to host mode. A container shares the host network stack, and all interfaces from the host are available to the container.
This is very convenient because it allows you to access your docker container from pretty much any port. However, only a few ports are actually open and configured in the VPC Network > Firewall settings for security reasons. For the SSH connection I decided to open a custom port 52241. You can do this in your GCP Console under VPC Network > Firewall or with the following gcloud command-line tool.
|
|
gcloud compute firewall-rules create custom-allow-ssh --allow tcp:52241 --priority=65534 --description="Allow SSH connections on port 52241" --direction=INGRESS |
|
|
gcloud compute firewall-rules create custom-allow-ssh --allow tcp:52241 --priority=65534 --description="Allow SSH connections on port 52241" --direction=INGRESS Creating firewall...⠹Created [https://www.googleapis.com/compute/v1/projects/tobiasforkel/global/firewalls/custom-allow-ssh]. Creating firewall...done. NAME NETWORK DIRECTION PRIORITY ALLOW DENY DISABLED custom-allow-ssh default INGRESS 65534 tcp:52241 False |
Once completed, here is how the new firewall rule looks like in the console. If you scroll down, you will also see all affected instances.
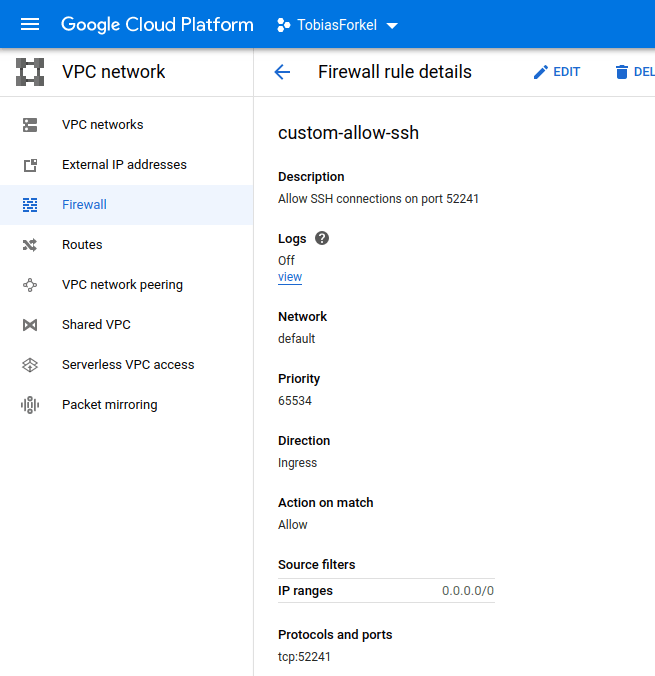
Before you can SSH into your container on port 52241 you must change the port in the sshd configuration /etc/ssh/sshd_config within your container or container image. Not on the VM.
|
|
Port 52241 PermitRootLogin no PermitEmptyPasswords no ChallengeResponseAuthentication no PrintMotd yes AcceptEnv LANG LC_* |
You may have to restart your ssh service before you can use the new port. Once this is done, you can SSH into your docker container.
|
|
ssh tobias@34.73.237.216 -p 52241 tobias@34.73.237.216's password: Welcome to Alpine! The Alpine Wiki contains a large amount of how-to guides and general information about administrating Alpine systems. See <http://wiki.alpinelinux.org/>. You can setup the system with the command: setup-alpine You may change this message by editing /etc/motd. |