
Today was a strange day. I’ve launched a new version of my docker image within an ECS cluster, which usually worked fine. However, today my container always got recreated every 5 minutes for no reason.
The new docker image that I have pushed to the repository had no significant changes, except a redirect from non-SSL ( 80 ) to SSL ( 443 ) for all loaded virtual hosts. So, when I had a look at the processes, everything looked fine. There was nothing that could put the container into an unhealthy status.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
PID USER TIME COMMAND 1 root 0:02 {supervisord} /usr/bin/python2 /usr/bin/supervisord -c /etc/supervisord.conf 8 root 0:00 nginx: master process /usr/sbin/nginx -g daemon off; 9 root 0:00 {mysqld.sh} /bin/sh /scripts/mysqld.sh 10 root 0:00 /usr/sbin/crond -f 13 nginx 0:13 nginx: worker process 35 root 0:00 {php-fpm7.1} php-fpm: master process (/etc/php/7.1/php-fpm.conf) 90 root 0:00 {mysqld_safe} /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mysql 288 mysql 0:08 /usr/bin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib/mariadb/plugin --user=mysql --log-error=/var/lib/mysql/f817894c1752.err --pid-file=f817894c1752.pid --socket=/var/run/my 3620 www-data 0:06 {php-fpm7.1} php-fpm: pool www 3621 www-data 0:05 {php-fpm7.1} php-fpm: pool www 3668 www-data 0:02 {php-fpm7.1} php-fpm: pool www 3795 root 0:00 bash 3807 root 0:00 ps aux |
Even the log output of the docker container didn’t show any error. After a little bit of research, I ended up on the following AWS developer guide page https://docs.aws.amazon.com/AmazonECS/latest/developerguide/update-service.html
|
1 |
When the service scheduler replaces a task during an update, the service first removes the task from the load balancer (if used) and waits for the connections to drain. Then, the equivalent of docker stop is issued to the containers running in the task. This results in a SIGTERM signal and a 30-second timeout, after which SIGKILL is sent and the containers are forcibly stopped. If the container handles the SIGTERM signal gracefully and exits within 30 seconds from receiving it, no SIGKILL signal is sent. The service scheduler starts and stops tasks as defined by your minimum healthy percent and maximum percent settings. |
It was not exactly what I was looking for, but it pretty much explained the problem I had. One of my colleagues said I should maybe have a look at the health checks of the load balancer.
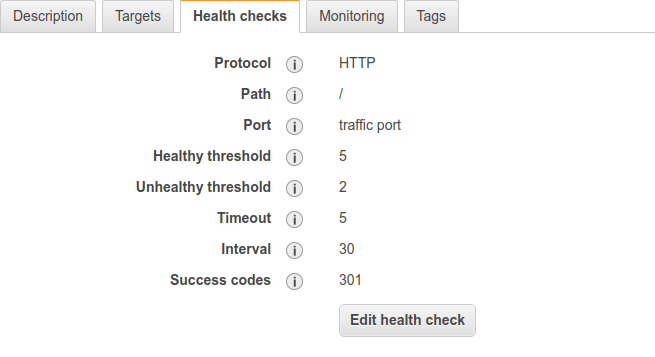
Indeed, when I had a look at the settings in EC2 > Load Balancing > Target Groups > Health Checks the health check expected a success code 200 instead of 301 on port 80. Because of that, the container has been marked unhealthy every 5 minutes.
I hope this will point someone in the right direction.
I assume you’re using the EC2 hosted mode of ECS (and not farget)